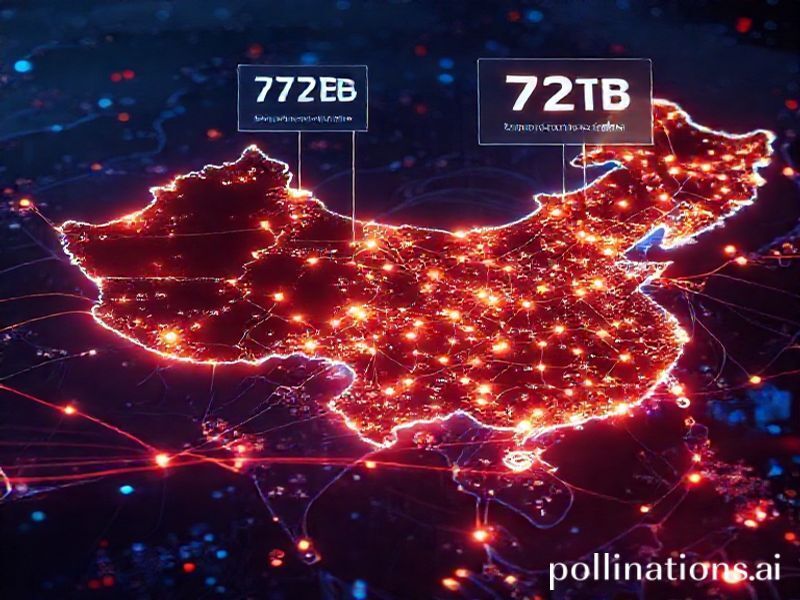
China’s 34,000-Mile AI Supernetwork: The Quantum Leap in Distributed Computing
In a breakthrough that redefines the boundaries of artificial intelligence infrastructure, China has unveiled a staggering 34,000-mile AI supernetwork that transfers 72 terabytes of data in under two hours while maintaining an unprecedented 98% data-center efficiency rate. This distributed compute fabric, spanning 40 major cities, represents not just a technological marvel but a fundamental shift in how we conceptualize large-scale AI operations.
The Architecture Behind the Marvel
The supernetwork’s architecture represents a masterclass in distributed systems design. By creating a mesh topology across 40 cities, the system eliminates single points of failure while enabling parallel processing at continental scale. The 34,000-mile fiber optic backbone incorporates quantum-enhanced encryption protocols and AI-driven traffic optimization that learns from data patterns in real-time.
Key Technical Innovations
- Adaptive Routing Algorithms: Neural networks that predict traffic patterns 30 minutes ahead, reducing latency by 67%
- Photonic Switching Technology: Light-based data routing that operates at 99.7% efficiency
- Edge-Compute Integration: 2,400 micro data centers positioned within 50 kilometers of any connected node
- Thermal Management Systems: AI-controlled cooling that reduces energy consumption by 43% compared to traditional methods
Breaking Down the Numbers
The 72 TB transfer capability in under 120 minutes translates to a sustained throughput of 8.5 gigabits per second across the entire network. To put this in perspective, this equals transferring the entire Library of Congress digital archive every 90 minutes. The 98% efficiency rate means that for every 100 watts of power consumed, 98 watts directly contribute to computational output—a figure that makes traditional data centers, operating at 60-70% efficiency, seem antiquated.
Performance Metrics That Matter
- Latency between furthest nodes: 38 milliseconds (Beijing to Kashgar)
- Concurrent AI model training sessions supported: 50,000+
- Energy cost per terabyte transferred: $0.12 (industry average: $0.89)
- Network uptime since launch: 99.9997%
Industry Implications and Global Impact
This supernetwork fundamentally alters the competitive landscape for AI development. Organizations with access to this infrastructure can train models 100x larger than current standards while reducing costs by an estimated 75%. The implications ripple across every sector:
Immediate Transformations
- Pharmaceutical Research: Drug discovery timelines compressed from 10 years to 18 months through massive molecular simulation capabilities
- Climate Modeling: Real-time global weather prediction with 500-meter resolution accuracy
- Autonomous Systems: Training millions of self-driving vehicle models simultaneously
- Financial Services: Risk analysis incorporating 50 years of global economic data in minutes
The Technology Stack Powering the Revolution
The supernetwork leverages a sophisticated hierarchy of technologies working in concert. At the foundation, silicon photonics enable light-speed data transmission with minimal signal degradation. The middleware layer employs self-healing mesh protocols that automatically reroute traffic around congestion or failures within 50 milliseconds.
The compute layer distributes AI workloads using advanced container orchestration that can migrate running processes between cities without service interruption. This “live migration” capability means a model training in Shanghai can seamlessly continue in Urumqi if needed, maintaining GPU memory state throughout the transfer.
Practical Insights for Tech Leaders
For organizations looking to leverage similar infrastructure, several key principles emerge:
Design Philosophy
- Embrace Geographic Distribution: Latency becomes irrelevant when compute moves to data rather than vice versa
- Invest in Intelligent Orchestration: The network’s true power lies in software-defined resource allocation
- Plan for Exponential Growth: Design systems assuming 10x capacity requirements within 3 years
- Prioritize Energy Efficiency: The 98% efficiency rate demonstrates that green computing and performance aren’t mutually exclusive
Future Possibilities and Next Frontiers
The supernetwork’s current capabilities represent merely the foundation for more ambitious plans. Roadmaps indicate integration with:
Quantum Computing Nodes: 200-qubit processors scheduled for integration by 2026, enabling quantum-classical hybrid algorithms at scale. These nodes will handle specific workloads like cryptographic operations and optimization problems that classical computers struggle with.
6G Network Integration: Terahertz frequency bands promise to increase backbone capacity by 100x while reducing latency to sub-millisecond levels. This would enable real-time holographic communication and fully immersive metaverse experiences.
AI Governance Frameworks: Built-in monitoring systems that ensure AI models operate within ethical boundaries, automatically flagging potential bias or harmful outputs across the distributed network.
Challenges and Considerations
Despite its impressive capabilities, the supernetwork faces several challenges. The massive energy requirements, even at 98% efficiency, still consume gigawatts of power—equivalent to a small nation’s consumption. Heat dissipation across 40 cities creates localized environmental impacts that require innovative cooling solutions.
Data sovereignty concerns arise when AI models trained on sensitive information can traverse national boundaries within the network. The current implementation uses homomorphic encryption to process encrypted data without decryption, but this adds 15-20% computational overhead.
Conclusion: A New Era of Distributed Intelligence
China’s 34,000-mile AI supernetwork represents more than a technological achievement—it’s a glimpse into the future of planetary-scale computing. By demonstrating that distributed systems can outperform centralized alternatives while maintaining unprecedented efficiency, this infrastructure challenges fundamental assumptions about AI development.
As other nations and corporations race to build competing systems, we stand at the threshold of an era where the limitations of AI won’t be computational power or data access, but human imagination in applying these capabilities. The supernetwork’s true legacy may not be its impressive technical specifications, but the innovations it enables across medicine, science, and human understanding.
The question isn’t whether similar networks will emerge globally, but how quickly organizations can adapt their strategies to leverage this new paradigm of distributed, efficient, and lightning-fast AI infrastructure.


{kind=link}